Hackerrank: Maximal Tourism (C++)
Today I want to take an in-depth look at a programming question I worked out earlier. You can view the the problem statement here. I recommend giving it a good try yourself before reading the rest of this post!
Understanding the problem
The first thing I always do when solving a technical question is break down the question into something I can understand. Often, problem statements will describe a “real world” scenario, which gives the problem some credence, but can also divert your attention away from the underlying problem that needs to be solved. Here, the problem statement can be interpreted using graphs and graph theory.
Note that the following may not make so much sense if you know nothing about graphs or graphs theory. Going into the detailed basics is outside the scope of this blog post, but I definitely recommend for you to learn - graphs appear in many technical questions.
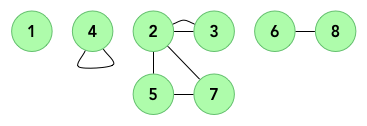
We can see right away that graphs are going to be a great help in figuring out this question. If the description didn’t give it away, the picture (shown above) should have. Here we are going to have an undirected, unweighted, and, more than likely, unconnected graph. The vertices are going to be the cities and the edges are going to be the connections between them.
Next is to interpret the question: “What is the maximum number of cities Jason can visit?”. Essentially, Jason wants to find the size of the largest “group” of cities that are connected (I will be using “group” from now on to refer to a set of cities that are connected).
Creating a strategy
Essentially what we want to be doing is, for every group, count the number of cities in that group. Then, out of all of these counts, the maximum count is the answer.
So, how do we go about counting the number of cities in a group? Let’s assume we start with any given city. Then, we can use breadth-first search to reach all the connected cities, maintaining a count as we go (a depth-first search would perform just as well, but I usually prefer BFS). When BFS finishes, we know that we have reached and counted all the connected cities exactly once (in other words, we do not count the same city twice) in that group. This fact just comes from some general intuition about BFS.
We are going to have to repeat the above process for every city. But, we only want to consider each group. Therefore, we will not have to repeat the process for any city that we have already visited - we know that city’s group was already counted, so it would just be extra work to count it again. In general, even though this does not reduce the time complexity, it is going to save our algorithm a lot of time.
Finally, maintain a running maximum during each iteration of the above procedure. A more concise version of this high level algorithm is as follows:
construct a graph
for each v in unprocessed cities
BFS starting from v
mark each city as discovered (remove from unprocessed cities)
increment a count
update maxCities
Data structures
Cities can simply be represented as an int. For the graph, I use an adjacency list:
unordered_map<int, vector<int>> adj
An adjacency list is a great way to store a graph that saves a lot of space compared to an adjacency matrix. Then to keep track of the processed cities, I use a hash table:
unordered_set<int> unprocessedCities
The unordered_set allows me to very quickly (O(1) time) and easily do a few things:
- Insert cities, uniquely, that needs to be processed
- Extract a city to be processed, and then erase that city
Note that, because the cities are given to be ints from 1 to n, vectors will also work here, and can save some of the complexity of the implementation.
And then, to perform the BFS, we are going to need the standard set of data structures: a queue and an unordered set to keep track of discovered vertices.
Implementation
1
2
3
4
5
6
7
8
9
10
11
12
int main() {
int n;
int m;
cin >> n >> m;
vector< vector<int> > route(m,vector<int>(2));
for(int route_i = 0;route_i < m;route_i++){
for(int route_j = 0;route_j < 2;route_j++){
cin >> route[route_i][route_j];
}
}
// Write Your Code Here
This code was provided by Hackerrank. Although you do not need to modify this code, it’s important to understand how to use route to access the input data: the ith edge is given as (route[i][0], route[i][1]).
Next, we construct our graph:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
unordered_set<int> unprocessedCities;
unordered_map<int, vector<int>> adj;
// Construct the graph
for (int i = 0; i < m; i++) {
int u, v;
u = route[i][0];
v = route[i][1];
if (!adj.count(u)) {
adj[u] = vector<int>{v};
} else {
adj[u].push_back(v);
}
if (!adj.count(v)) {
adj[v] = vector<int>{u};
} else {
adj[v].push_back(u);
}
unprocessedCities.insert(u);
unprocessedCities.insert(v);
}
We take (u,v) as our edge. If u is not in our adjacency list, we need to initialize an entry with a vector, which only contains a single element (v) for now. Otherwise, we just append v to the existing entry. We then repeat the same process for v, which we must do because we want an undirected graph (i.e., if (u,v) is an edge, then (v,u) is also). The syntax is ugly, but that’s just what happens sometimes when using C++ and the STL! ![]()
Finally, we add u and v to unprocessedCities. This way, we keep a collection of the cities we want to use for the next part of the algorithm. Note that this collection is is made up of unique elements - in the typical case, we will certainly be inserting multiple copies of the same city, but the unordered_set class takes care of it for us.
Finally, we have the group size counting portion of the algorithm:
1
2
3
4
int maxCities = 1;
while (!unprocessedCities.empty()) {
auto it = unprocessedCities.begin();
First we initialize maxCities to 1. The reasoning behing setting the value to 1 rather than 0 is because even when none of the cities are connected, Jason will always be able to travel to at least one.
Next we set up a while loop. What this loop does is run until we run out of cities to be processed. We then take the first element, which could be any arbitrary city, but we know that it is part of a group that still needs to be counted (any city whose group has already been counted will not be in this set, as we will see below).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Perform the BFS
unordered_set<int> discovered;
queue<int> vertices;
discovered.insert(*it);
vertices.push(*it);
int count = 0;
while(!vertices.empty()) {
int v = vertices.front();
vertices.pop();
unprocessedCities.erase(v);
count++;
for (int i = 0; i < adj[v].size(); i++) {
int u = adj[v][i];
if (!discovered.count(u)) {
vertices.push(u);
discovered.insert(u);
}
}
}
maxCities = maxCities > count ? maxCities : count;
}
This is just standard BFS with a couple of additions. The most important is line 11. Here we remove the current vertex from our unprocessedCities. The reason is that all vertices processed in a given iteration of the BFS (remember, we are running the BFS for each group) are a part of the same group, which is already being counted. So, each vertex is effectively processed. The second addition is just to increment our count as we go along.
Evaluating the algorithm
First, does the algorithm work? For typical cases, it should: each group is processed and counted once, and the max of all those counts is taken - exactly what is required. What about some edge cases? Here I list a few:
- An empty graph
- Trick question! An empty graph is not a valid input. Remember, don’t waste time handling edge cases that don’t exist.
- A completely disconnected graph (i.e., no cities are connected to each other)
- Technically, this is not actually valid input - one connection will always be given. But this edge can be a city connected to itself. In this case, our algorithm would process that one city (and only that one city - notice we only process cities that have an edge connected to them), and return 1, which is the desired behavior.
- A graph with multiple connections between the same two cities
- This is no problem - at worst, a vertex will have multiple copies of the same vertex in its list, but thanks to our
discoveredset in BFS, that duplicated vertex will not be counted twice.
- This is no problem - at worst, a vertex will have multiple copies of the same vertex in its list, but thanks to our
The time complexity is O(n+m). The n term comes from our many iterations of BFS. Though it may seem that this number is greater than just n, remember that we only perform BFS on each group once, for each group. Therefore the amount of steps in all the BFS combined is the sum of the number of members in each group, which is just all the elements, which is n. The m term comes from the creation of the graph, where we process each of the m edges.
Final thoughts
The basic idea behind this problem was relatively simple, and there was nothing too tricky in the implementation. The hardest parts are remembering (or perhaps just learning!) how to create a graph (adjacency list) and how to perform BFS. But, these things are important, so it is good to have a problem to practice them!
Complete solution
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
// https://www.hackerrank.com/contests/rookierank-3/challenges/maximal-tourism
#include <bits/stdc++.h>
using namespace std;
int main() {
int n;
int m;
cin >> n >> m;
vector< vector<int> > route(m,vector<int>(2));
for(int route_i = 0;route_i < m;route_i++){
for(int route_j = 0;route_j < 2;route_j++){
cin >> route[route_i][route_j];
}
}
// Write Your Code Here
unordered_set<int> unprocessedCities;
unordered_map<int, vector<int>> adj;
// Construct the graph
for (int i = 0; i < m; i++) {
int u, v;
u = route[i][0];
v = route[i][1];
if (!adj.count(u)) {
adj[u] = vector<int>{v};
} else {
adj[u].push_back(v);
}
if (!adj.count(v)) {
adj[v] = vector<int>{u};
} else {
adj[v].push_back(u);
}
unprocessedCities.insert(u);
unprocessedCities.insert(v);
}
int maxCities = 1;
while (!unprocessedCities.empty()) {
auto it = unprocessedCities.begin();
// Perform the BFS
unordered_set<int> discovered;
queue<int> vertices;
discovered.insert(*it);
vertices.push(*it);
int count = 0;
while(!vertices.empty()) {
int v = vertices.front();
vertices.pop();
unprocessedCities.erase(v);
count++;
for (int i = 0; i < adj[v].size(); i++) {
int u = adj[v][i];
if (!discovered.count(u)) {
vertices.push(u);
discovered.insert(u);
}
}
}
maxCities = maxCities > count ? maxCities : count;
}
cout << maxCities << endl;
return 0;
}